PINTOS 설명 및 수행과제
- OS프로젝트는 PintOS의 코드를 직접 수정해가며 진행하는 프로젝트이다.
- PintOS는 2004년 스탠포드에서 만들어진 교육용 운영체제이다. 정글에서는 이를 기반으로 KAIST 권영진 교수님 주도 하에 만들어진 KAIST PintOS로 운영체제 학습을 시작했다.
- Pintos week1 수행 주제는 'Thread'이다. thread의 scheduling algorithm을 develop해가며 학습이 진행되었다.
- 처음에 기본으로 주어지는 pintos code는 정상적으로 작동하되 부분적으로 비효율적으로 구동하게끔 구성되어 있다. 비효율적으로 작동하는 부분들을 개선시키며 과제들을 PASS 시킨다.
- 총 3가지 문제로 구성되어 있으며 첫 번째 문제인 alarm clock문제를 해결하며 Thread status에 대한 감을 잡는다. 이어지는 문제에서 주어지는 issue에 따라 scheduling algoritm을 발전시킨다.
WIL Key word
- Alarm clock : busy-wait, interrupt (timer, event driven)
- Priority scheduling (1) : thread waiting list priority, semaphore waiting list
- Priority scheduling (2) : Priority donation ( priority inversion problem )
- Advanced scheduler : BSD scheduler
1. Alarm Clock ( timer_sleep( ) )
PINTOS 첫 과제는 busy wait 방식으로 구현되어 있는 timer_sleep 함수를 개선하는 것.
문제 해결에 앞서 Thread가 가질 수 있는 status에 대한 기본적인 지식이 필요했다.
Thread status - Kernel에 의해 schedule 되는 thread들의 status는 4가지가 존재한다.
THREAD_RUNNING
The thread is running. Exactly one thread is running at a given time.
THREAD_READY
The thread is ready to run, but it's not running right now. The thread could be selected to run the next time the scheduler is invoked.
THREAD_BLOCKED (=WAITING)
The thread is waiting for something, e.g. a lock to become available, an interrupt to be invoked. The thread won't be scheduled again until it transitions to the THREAD_READY state with a call to thread_unblock()
THREAD_DYING (INACTIVE)
The thread will be destroyed by the scheduler after switching to the next thread.
1. 처음 create 될 때, thread는 Ready status를 부여 받으며 priority에 따라 선점이 일어나면 바로 Running status 로 변경되기도 한다.
2. running 되는 code에서 발생하는 특정 event 혹은 timer에 의한 interrupt에 의해 thread의 상태는 다른 상태로 변경될 수 있다.
인지해야 하는 중요한 부분은 CPU에서 running 되기 직전에는 READY status에 있어야 한다는 부분이다. BLOKED(WAITING) 상태에서는 커널이 다음에 CPU에서 Running할 thread로 고려하지 않기 떄문에 Running 상태가 되기 위해서는 Ready 상태로 먼저 변경되어야 한다.
(BLOCK 상태는 READY list와 구분 관리하기 위한 일종의 격리상태라고 이해했다.)
3. 여기서 말하는 timer interrupt는 system에서 특정 시간 간격으로 발생시키는 signal에 의한 interrupt이다. 운영체제의 목적 중 하나인 concurrency를 가능하게 하는 핵심 기능이다. pintos에서는 특정 쓰레드가 CPU를 4tick 이상 점유하게되면 context switching이 발생하도록 초기 셋팅되어 있다.

Alarm clock에서 수정되어야 하는 timer_sleep( ) 함수는 인자 값으로 주어지는 tick단위의 시간만큼 쓰레드를 잠재우는 기능이다. (tick은 시스템에서 특정 작업 기준점으로 사용하기 위한 시간단위이다. 여기서는 timer interrupt 관리를 위해 사용된다. 기본 셋업이 TIMER_FREQ = 100으로 셋업되어 있는데, 1tick = 1/100sec으로 환산 가능하다.)
Busy wait
busy wait은 running 쓰레드가 다른 쓰레드에게 선점(preempt) 되었을 때, BLOCKED 상태가 아닌 READY 상태로 변경하여 대기함을 의미한다.
문제상황
busy wait으로 timer_sleep 함수가 구현되면 왜 문제가 되는지 생각해볼 필요가 있다.
busy wait으로 구현된다면 timer_sleep ( ) 함수는 쓰레드가 재개되는 조건을 만족할 때까지 다음처럼 상태 변경 하게된다.
'RUNNING -> READY -> RUNNING -> READY ···················'
(RUNNING에서 awake 조건을 만족하는지 확인하고 만족되지 못할 경우 다시 READY를 반복한다.)
CPU는 컴퓨터에서 귀한 hardware 자원 중 하나이기 때문에 목적에 맞게 효율적으로 사용되는게 중요하다. 위와 같이 구현되면 CPU의 낭비가 발생한다.
해결 방법
이상적으로는 event에 대한 조건을 만족할 때까지 해당 쓰레드를 BLOCK하고, 조건이 만족되었을 때 비로소 READY 상태로 변경되도록 코드를 변경해주어야 한다.
timer_sleep : 함수가 실행되면 해당 쓰레드가 block 되도록 변경했다.
SLEEP_LIST : sleep에 의해 block된 쓰레드 관리를 위한 별도 list 를 구조체를 작성했다.
AWAKE : sleep 시간이 지나면 BLOCK -> READY로 변경되도록 새로운 함수를 작성했다.
이러한 방법을 통해 timer_sleep 함수를 개선했다.
꼭 알아둬야 하는 점은 busy wait이 언제나 비효율적인 건 아니라는 점이다. running 중이던 쓰레드가 block되는 상황이 자주 발생하지만, block에서 ready로 unblock되는 event의 발생 term이 충분히 짧은 상황이 있을 수 있다. 이러한 경우에는 위와 같이 block list를 관리하는 것이 overhead가 더 크기 때문에 busy wait보다 비효율 적일 수 있다.
2. Priority Scheduling (Thread waiting list priortization)
Pintos scheduler에 초기 setting된 algorithm을 개선한다.
문제 상황
- 스케줄러가 round-robin으로 구현되어 있으며 우선순위를 고려하지 않아서 우선순위와 무관하게 실행된다.
- ready list에 추가되는 thread는 항상 맨 뒷부분에 추가되고, next running thread는 list의 제일 앞에 있는 thread이다.
해결 목표
- ready_list가 우선순위 순으로 관리 (priortization)
- 더 높은 우선순위의 thread가 생성되면 기존 thread를 밀어내고 선점하여 실행 (preemption)
- list 내 동일한 우선순위에서는 round-robin
라운드 로빈 스케줄링 - 위키백과, 우리 모두의 백과사전
ko.wikipedia.org
- OS GitBook 1주차 FAQ
If the highest-priority thread yields, does it continue running?
Yes. If there is a single highest-priority thread, it continues running until it blocks or finishes, even if it calls thread_yield(). If multiple threads have the same highest priority, thread_yield() should switch among them in "round robin" order.- 우선순위가 가장 높은 thread가 1개일 경우, 혼자 계속 실행됨
- 우선순위가 가장 높은 thread가 2개 이상일 경우, 동일한 우선순위 내에서 round robinpint
- 쓰레드 문맥전환 발생 상황
- 전제 1. Interrupt 발생 case
- Timer Interrupt
- 내장된 타이머(PIT)가 주기적으로 보내는 thread 변경 신호가 발생한 경우
- Interrupt with event
- 현재 thread가 특정 조건이 충족되기까지 기다려야 하는 경우
- 더 높은 우선순위의 thread가 생성된 경우
- 기타 특정한 이벤트가 발생한 경우
- Timer Interrupt
- 전제 2. 우선순위가 반영된 ready_list (현재 문제의 개선 사항)
- ready_list가 우선순위 순으로 관리됨
- 더 높은 우선순위의 thread가 생성되면 기존 thread를 밀어내고 실행됨
- 전제 1. Interrupt 발생 case
- 수정 후 작동 과정
- 우선순위가 가장 높은 thread가 1개일 경우
- CPU를 점유하는 중에도 정기적인 변경 요청에 의해 ready_list에 일단 추가됨 (thread_yield() 참고)
- 이 때 현재 thread는 우선순위가 가장 높으므로 ready_list의 가장 앞에 배치됨 (list_insert_ordered() 참고)
- scheduler가 ready_list에서 가장 앞에 놓인 thread를 다음 thread로 변경하려 하지만, 현재 thread와 다음 thread가 동일하기 때문에, 변경되지 않고 그대로 유지됨 (schedule() 참고)
- 우선순위가 가장 높은 thread가 2개일 경우
- 정기적 변경 요청에 의해 ready_list에 추가됨
- 이 때 현재 thread와 우선순위가 동일한 thread가 ready_list에 대기중이었으므로, 현재 thread와 우선순위가 동일한 thread들 중 가장 뒤에 배치됨 (thread_compare_priority() 참고)
- scheduler가 ready_list에서 가장 앞에 놓인 thread를 다음 thread로 변경하며 이에 따라 동일한 우선순위의 thread들 간에 round robin이 발생함
- 우선순위가 가장 높은 thread가 1개일 경우
3. Synchronization
개요
- 기존 상황 및 문제점
- 개선 사항
살펴보기: monitors
- https://casys-kaist.github.io/pintos-kaist/appendix/synchronization.html
- monitor의 3가지 구성요소
- data being synchronized: 공유 자원
- monitor lock: 공유 자원에 대한 접근 권한
- condition variables: 공유 자원의 상태 정보
- 대표 예시: Producer Consumer Problem
- data: 4칸의 책장
- monitor lock: 책장 접근 권한
- PUTTER: 책 1권 추가하기 (Put or Produce)
- GETTER: 책 1권 가져가기 (Get or Consume)
- condition variables: 책장의 상태
- not_empty: 책장에 책이 1권 이상 있는지 여부
- waiters: 책장에 책이 없다면 책이 추가되기를 기다리는 대기열
- not_full: 책장에 책이 4권으로 가득 찼는지 여부
- waiters: 책장이 가득 찼다면 빈 공간이 생기기를 기다리는 대기열
- not_empty: 책장에 책이 1권 이상 있는지 여부
- 발생 가능 시나리오
- 책장은 비어 있는 상태임
- 우선 책장에 GETTER 접근
- 책장에 GETTER가 접근 권한을 가지고 접근해 1권 가져가려 하며, 책장의 상태가 non_empty인지 확인
- non_empty가 false이기 때문에 책이 추가되기를 기다려야 하고, 이를 위해 접근 권한을 일단 반납한 뒤 본인은 not_empty waiters에 들어감
- 그 다음 책장에 PUTTER 접근
- 책장에 PUTTER가 접근 권한을 가지고 접근해 1권을 추가하려 하며, 책장의 상태가 non_full인지 확인 (이 때 접근 권한은 앞서 GETTER가 반납한 것)
- non_full이 true이기 때문에 책을 바로 추가
- 책을 추가한 뒤 책이 추가되기를 기다리는 thread가 있을 수 있기 때문에 non_empty가 해결되었다는 Signal을 보냄
- 접근 권한이 waiters에 있는 GETTER에게 다시 넘어감
- 다시 GETTER 차례
- 책장이 책이 1권이 있기 때문에 이번에는 non_empty 통과
- 책을 1권 가져간 뒤 책장이 비기를 기다리는 thread가 있을 수 있기 때문에 non_full이 해결되었다는 signal을 보냄
- 접근 권한을 반납한 뒤 종료
4. Priority scheduler ( Inversion Problem )
상기 서술한 우선순위 문제를 해결하더라도 Priority inversion problem이라고 불리는 문제가 남아있다.
문제상황은 다음과 같다.
문제 상황
1. 특정 공유자원에 대하여 낮은 우선순위(L)의 쓰레드가 lock을 점유하고 lock 반납 이전에 context switching 발생
2. 높은 우선순위(H)의 쓰레드의 lock aquire 요청
이러한 상황에서 H,L 중간 쓰레드가 없다면, 쓰레드 H는 waiter list로 가게되고 쓰레드 L의 lock release 이후에 다시 재개하게된다.
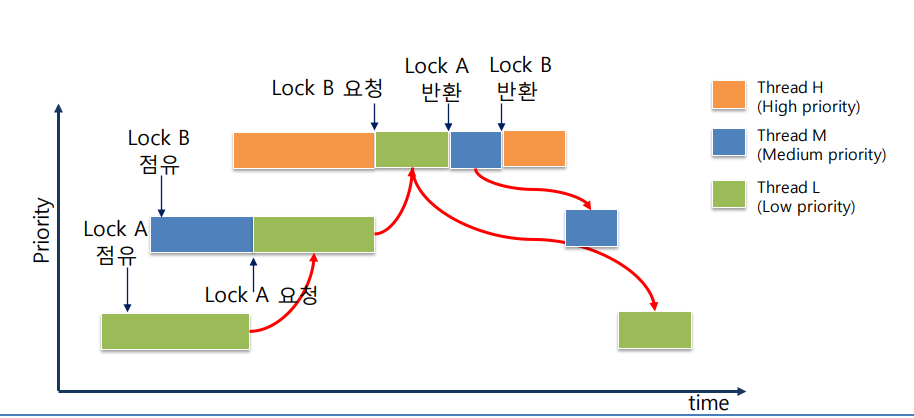
그런데, 만일 H, L 중간의 우선순위 값을 갖는 M 쓰레드가 있는경우, 하기 이미지처럼 M과 H의 우선순위가 역전되는 문제가 발생한다. M 우선순위의 쓰레드의 개수가 많을수록 H의 우선순위는 계속 밀리게된다. 실제 운영체제가 돌아가는 환경에서는 중간값을 갖는 우선순위의 개수가 많을 가능성이 높기 때문에 더 크게 문제된다.
발생 가능한 문제 유형
Pintos에서는 donation 알고리즘이 잘 적용되었는지 확인하는 목적으로 3가지 유형의 test case가 존재한다.
Donate-one, Multiple donation, Nested donation
- Donate-one case는 그림과 같이 3단계의 우선순위가 존재하는 경우이다.
- Multiple donation은 lock holder가 2개의 서로 다른 자원의 key를 가지고 있고, 서로 다른 우선순위의 쓰레드가 해당 자원들에 접근하는 경우이다.
- Nested donation case는 하기 이미지와 같이 낮은 우선순위의 쓰레드가 높은 우선순위가 필요로하는 lock을 가지고 있는데 이러한 상황이 단계적, 연속적으로 발생하여 Nested 된 경우다.
유형은 3가지이지만, 알고리즘이 잘 짜져있는지 확인하는 목적이기 때문에 근본적인 문제 해결방법이 다르지 않다.
문제별 풀이 사고 과정.



해결 방법
문제 해결방법으로는 lock holder가 lock waiter의 priority 보다 낮은 경우 lock holder에게 lock waiter중 가장 높은 우선순위를 갖는 쓰레드의 priority를 부여하는 것이다.
Pintos 1주차 회고
잘한 점
- 구현한 범위까지는 잘 이해했음
- 처음부터 구현에 급급하기보다 필요한 지식들을 충분히 습득하고 문제를 충분히 이해할 시간을 갖음.
- 초반에는 거의 대부분의 코드를 웹 상에 나온 solution들에 의존했지만, 점차 로직을 직접 고민해보는 시간을 늘려감
- 해결한 문제들에 대해서는 충분히 이해하며 다음 단계로 넘어갔음
- 팀원들과 적극적으로 소통하며 프로젝트를 진행했음
- 문제를 이해하고 해결 방안을 고민하는 과정을 모두 함께 진행함
- Github을 활용해 프로젝트 레포를 관리했음
- 하위 문제 단위로 프로젝트를 나누어 진행
- 자체적인 repository 관리 정책을 정해 진행
- 팀원들 모두 1회 이상 Pull Request를 올려 master에 merge하는 경험
아쉬운 점
- CSAPP 3장을 읽지 못한점
- 커널의 Context switching 부분 코드가 어셈블리어로 작성되어 있었는데, 이해하지 못하고 핀토스가 끝난 점이 아쉽다. (Context save, load 부분)
- solution 없이 구현하려는 시도가 부족했음
- 다른 사람의 풀이를 너무 빨리 본다 생각이 들었음
- testcase를 중심으로 문제를 파악하고 해결 방법을 고민해보는 시간을 조금더 빨리 그리고 길게 가져가면 좋겠음!
- 상대적으로 혼자 고민하며 정리할 수 있는 시간이 부족했음
- 다른 팀과의 교류가 부족했음
- 테스트를 더 쉽게 할 수 있는 팁이나 좋은 자료들을 뒤늦게 알게 됨
- 다음 주차에는 강의실에 놀러도 가고 다른 팀을 초대도 하자!
'컴퓨터 시스템 > OS' 카테고리의 다른 글
| 컴퓨터 시스템/OS [WIL] 컴퓨터 운영체제 ' File System' (pintos project 4) - 작성 중 (0) | 2021.10.30 |
|---|---|
| 컴퓨터 시스템/OS [WIL] 컴퓨터 운영체제 ' Virtual memory ' (pintos project 3) (2) | 2021.10.28 |
| ELF 파일구조 및 헤더 (0) | 2021.10.19 |
| [WIL] 컴퓨터 운영체제 'USER PROGRAMS' (pintos week2) - 작성 중 (0) | 2021.10.14 |
| OS review / Youngjin Kwon (0) | 2021.10.01 |